| Seguridad de la clave/PIN | [Alta, Media, Baja] | | Variable nominal |
| Cantidad a transferir | x | | Variable numérica |
| Geolocalización de cuentas destino | y[n] | | Variable cadena |
| ¿Noche o día? | 0/1 | | Variable binaria |
| ¿Robo? | Si/No 0/1| Clase, predicción o decisión a tomar, es binaria en este caso. | |
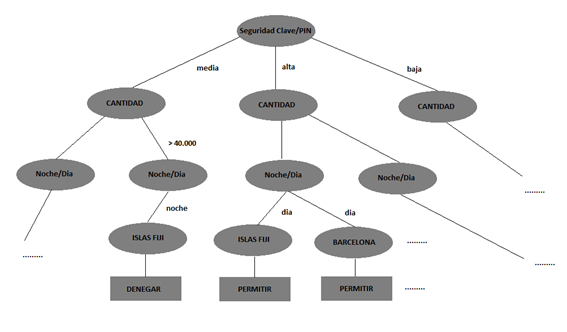
| Fig1: Modelo lógico de nuestro agente. |
| IP-origen [192.168.1.2, 10.10.10.10, 8.8.8.8,…] | | Variable nominal |
| TCP-flags [0.0.0.1.1.0.0.0.0, 0.0.0.0.0.0.0.0.1,…] NS,CWR,ECE,URG.ACK.PSH.RST.SYN.FIN |
|Variable nominal |
| Diff de tiempo – respecto trama anterior (ms) y | | Variable numérica |
| 10.10.1.4 | 0.0.0.0.0.0.0.1.0 | 0 | |||
| 10.10.1.4 | 0.0.0.0.0.0.0.1.0 | 1 | |||
| … | |||||
| 10.10.1.4 | 0.0.0.0.0.0.0.0.0 | 5 | |||
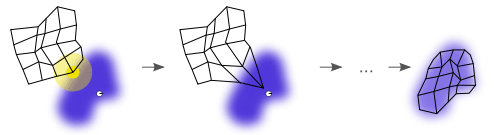
| Fig2: La retícula se ajusta sobre el espacio de soluciones. |
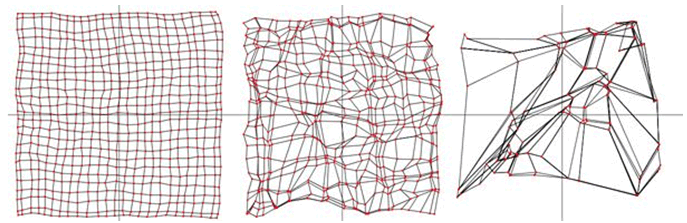
| Fig3: Además de ajustarse los nodos de la retícula se concentran, aumentan la densidad de estos en las zonas más representativas del espacio de soluciones. |
{kind=link}
{kind=link}
{kind=link}