En este artículo vamos a hacer una introducción de como las técnicas de “
machine learning” o aprendizaje automático son aplicadas al campo de la seguridad informática. Nuestra intención es familiarizar al lector con los conceptos fundamentales y ejemplos que serán necesarios para profundizar en enfoques prácticos y/o teóricos.
¿Qué es “machine learning”?
Machine learning es una rama de la inteligencia artificial que aplica el uso de modelos matemáticos como conductor de conocimiento a automatismos. Dicho de otra manera, es posible incorporar conocimiento de la naturaleza en un modelo matemático, al ser éstos funciones matemáticas son asimilables por automatismos, y como resultado tendremos un agente artificial que habrá aprendido dicho conocimiento.
¿Cómo se transmite el conocimiento desde la naturaleza al modelo?
La manera de incorporarlo es mediante entrenamiento, el cual hará aprender al modelo. Hay dos tipos de aprendizaje principales, supervisado y no supervisado, y de la combinación de estos o la incorporación de características específicas se identifican otros más. El término supervisado hace referencia a que el entrenamiento incorporará información etiquetada, es decir, ejemplos resueltos. En el caso del aprendizaje no supervisado no contaremos con dicha información, también llamada “ conocimiento a priori”, pero como veremos en un ejemplo más adelante, esto no imposibilita que se descubra a la vez que queda “impreso” en el modelo algunos tipos de conocimientos, por ejemplo relaciones de similitud.
¿Cómo queda “impreso” el conocimiento en el modelo?
Pues depende del modelo, hay infinidad de ellos pues al fin y al cabo son funciones matemáticas. El conocimiento puede quedar “ mapeado” en estructura de árbol o red (en modelos lógicos), conjunto de reglas probabilísticas (modelo probabilístico), áreas de similitud (modelos geométricos), etc.
¿Cómo aplica el modelo lo aprendido?
La clave de la aplicación de lo aprendido por el modelo está en el proceso llamado clasificación. Es decir el autómata consultará al modelo entrenado un hecho descrito mediante un vector de entrada, el modelo clasificará dicha entrada en una de las clases aprendidas (aprendizaje supervisado) o descubiertas (aprendizaje no supervisado), y finalmente el agente actuará en consecuencia.
Llegados a este punto vamos a exponer algunos ejemplos reales y prácticos que hagan comprender todo lo anterior de manera práctica.
Aprendizaje supervisado + arboles de decisión
Supongamos un hipotético sistema orientado a detectar cuando una cuenta bancaria ha sido comprometida. Contaría por una parte de un cliente acompañando la correspondiente aplicación bancaria para dispositivo móvil y un servidor (agente Inteligente entrenado + base de datos) en el centro de operaciones del banco. El cliente envía por cada transacción el siguiente vector (entrada de N campos), que se almacena en la base de datos y tras ser procesada por el agente procede con la transacción, su bloqueo, exige doble factor de verificación o tan sólo registra un aviso en los históricos del sistema. De entrada consideramos sólo la decisión de si es robo o no para proceder con el bloqueo o no de la transacción.
Vector de entrada para nuestro sistema (minimalista) de detección de robo de cuentas:
Lo primero que haremos será entrenar el modelo con un conjunto de vectores de entrada de dimensión 4, como podemos ver los vectores están etiquetados, el quinto campo de cada entrada contiene una clase binaria 1/0 indicando que hay compromiso o no de la cuenta bancaria, o en consecuencia si se procede con anular o no la transacción. La decisión sobre qué información utilizar para el entrenamiento debe ser tomada por un analista con conocimiento en dicho campo y fundamentado en experiencias (incidentes) reales a ser posible.
Alta,1300,Barcelona,1,0
Media,400.000,Panamá,1,1
….
Baja,5,Fiyi,1,1
Tras el entrenamiento se generará un árbol de decisión. Dependiendo del algoritmo en cuestión dependerá como queden dispuestos los nodos, las hojas, la anchura y profundidad del árbol, etc. Pero el fundamento es el mismo, tener un mapa de características que nos guiará hasta una decisión recorriéndolo desde la raíz hasta una hoja.
Una vez definido el modelo, en este caso es un árbol de decisión, el autómata solo tendrá que seguir el árbol a través de los valores de los atributos hasta llegar a las hojas (decisiones). Por ejemplo para un cliente con una clave o PIN de fortaleza media, para una transferencia de más de 40.000$ en horario de noche (supongamos que de 8 PM a 8 AM) a una cuenta destino geolocalizada en Islas Fiji se lanzaría una acción de denegar la transferencia, exigir un segundo factor de autenticación o alertar de manera silenciosa a un equipo CERT de la entidad bancaria. Una de las características que nos gustaría destacar de este modelo ya que tenemos la oportunidad es la velocidad de respuesta (“ toma de decisión”), se puede observar que es un problema es de complejidad O{n} (orden n, recorrer en profundidad un árbol), lo cual lo hace muy indicado en entornos que requieran de respuesta ágil y sometidos a una tasa de consulta muy elevada.
Aprendizaje no supervisado + Mapa auto-organizado (redes de Kohonen)
El aprendizaje no supervisado puede parecer al principio más complicado de imaginar en funcionamiento. Pero con el siguiente ejemplo quedará claro cómo funciona y de paso mostramos uno de los modelos más interesantes como son los mapas auto-organizados ( Self-organizing Maps, SOM), ya que están inspirados en la biología, concretamente en la disposición de las neuronas relacionadas con el sentido del tacto.
Vamos ahora a suponer que nuestro sniffer de red registra tráfico y en lugar de comunicarlo a un IPS tradicional, que analizaría mediante una expresión regular (como hace Snort[1]) cada trama, crea con las características (campos de la trama, las flags TCP, IP origen, etc.) un vector de entrada y se lo pasa al modelo. Nuevamente el modelo responderá, veremos que de manera sutilmente distinta al ejemplo anterior, y al tratarse de un IPS de manera activa se tomará una decisión sobre dicho tráfico.
El modelo se crea mediante entrenamiento nuevamente, pero en este caso el conjunto está sin etiquetar, no hay información de si algo es “bueno o malo” o clase de pertenencia.
Sin entrar mucho en detalles diremos que inicialmente el modelo es una retícula, que conforme transcurre el entrenamiento los nodos irán ajustándose sobre los datos de entrenamiento, creando áreas de mayor densidad de nodos (grupos o clústeres).
Terminado el entrenamiento la maya queda “fijada”, ahora nuevamente se aplicará al modelo cada entrada correspondiente a los segmentos TCP capturados. El vector incidirá sobre la malla quedando asociado a una concentración de nodos (clúster) en función de la distancia y la densidad de nodos respecto del punto donde incidió.
A continuación se pueden dar dos situaciones:
Aplicaciones
A día de hoy el uso de técnicas de “ machine learning” está más extendido de lo que en principio podríamos pensar en productos relacionados con la seguridad como SIEM é IPS. Aunque su aplicación no es novedosa en el campo de la investigación no es así en el mercado tecnológico. Este último está muy condicionado por modas o revoluciones de lo nuevo y podemos ver la incorporación de estas técnicas a productos de gama alta o en servicios de monitorización, a veces envueltas en cierta aura de misterio y a precios desorbitados. Más ofuscado aún es su uso en aplicaciones propias y no comerciales para la detección de fraude o robo de cuentas por parte de bancos o aseguradoras. Por esto, uno de los casos de éxito al que nos gusta hacer referencia es el del proyecto M.U.S.E.S[3], el cual está financiado por fondos europeos y cuenta con forja de software[4] bajo licencia GPL. En su caso, aplicado a la implantación segura de la política empresarial “ Bring your own devices” (BYOD). Y que es un ejemplo válido de como más adelante se puede derivar a un producto comercial.
Conclusión
Las técnicas de “ machine learning” pueden ser una poderosa herramienta en manos de investigadores y proveedores de productos tecnológicos centrados en la seguridad informática. Fuera de modas y revoluciones de lo nuevo, su divulgación debe ser responsable y ética con las expectativas ofrecidas por el estado del arte actual. Ha sido nuestra intención durante el artículo el transmitir de manera lo más simple posible y sin entrar en conocimientos demasiado profundos, los conceptos básicos que son necesarios para comprender las técnicas que aplica. No nos hemos detenido demasiado en temas como la base matemática requerida para la construcción de sus modelos (base teórica), o librerías de desarrollo (base práctica), para dar más relevancia al conocimiento de los conceptos fundamentales y ejemplos de demostración. Por lo que queda como tema pendiente para futuros artículos.
Referencias
[1] https://www.snort.org/
[2] http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html
[3] https://www.musesproject.eu/
[4] https://github.com/MusesProject
Autor: Juan Luis Martín
Departamento Auditoría
¿Qué es “machine learning”?
Machine learning es una rama de la inteligencia artificial que aplica el uso de modelos matemáticos como conductor de conocimiento a automatismos. Dicho de otra manera, es posible incorporar conocimiento de la naturaleza en un modelo matemático, al ser éstos funciones matemáticas son asimilables por automatismos, y como resultado tendremos un agente artificial que habrá aprendido dicho conocimiento.
¿Cómo se transmite el conocimiento desde la naturaleza al modelo?
La manera de incorporarlo es mediante entrenamiento, el cual hará aprender al modelo. Hay dos tipos de aprendizaje principales, supervisado y no supervisado, y de la combinación de estos o la incorporación de características específicas se identifican otros más. El término supervisado hace referencia a que el entrenamiento incorporará información etiquetada, es decir, ejemplos resueltos. En el caso del aprendizaje no supervisado no contaremos con dicha información, también llamada “ conocimiento a priori”, pero como veremos en un ejemplo más adelante, esto no imposibilita que se descubra a la vez que queda “impreso” en el modelo algunos tipos de conocimientos, por ejemplo relaciones de similitud.
¿Cómo queda “impreso” el conocimiento en el modelo?
Pues depende del modelo, hay infinidad de ellos pues al fin y al cabo son funciones matemáticas. El conocimiento puede quedar “ mapeado” en estructura de árbol o red (en modelos lógicos), conjunto de reglas probabilísticas (modelo probabilístico), áreas de similitud (modelos geométricos), etc.
¿Cómo aplica el modelo lo aprendido?
La clave de la aplicación de lo aprendido por el modelo está en el proceso llamado clasificación. Es decir el autómata consultará al modelo entrenado un hecho descrito mediante un vector de entrada, el modelo clasificará dicha entrada en una de las clases aprendidas (aprendizaje supervisado) o descubiertas (aprendizaje no supervisado), y finalmente el agente actuará en consecuencia.
Llegados a este punto vamos a exponer algunos ejemplos reales y prácticos que hagan comprender todo lo anterior de manera práctica.
Aprendizaje supervisado + arboles de decisión
Supongamos un hipotético sistema orientado a detectar cuando una cuenta bancaria ha sido comprometida. Contaría por una parte de un cliente acompañando la correspondiente aplicación bancaria para dispositivo móvil y un servidor (agente Inteligente entrenado + base de datos) en el centro de operaciones del banco. El cliente envía por cada transacción el siguiente vector (entrada de N campos), que se almacena en la base de datos y tras ser procesada por el agente procede con la transacción, su bloqueo, exige doble factor de verificación o tan sólo registra un aviso en los históricos del sistema. De entrada consideramos sólo la decisión de si es robo o no para proceder con el bloqueo o no de la transacción.
Vector de entrada para nuestro sistema (minimalista) de detección de robo de cuentas:
| Seguridad de la clave/PIN | [Alta, Media, Baja] | | Variable nominal |
| Cantidad a transferir | x | | Variable numérica |
| Geolocalización de cuentas destino | y[n] | | Variable cadena |
| ¿Noche o día? | 0/1 | | Variable binaria |
| ¿Robo? | Si/No 0/1| Clase, predicción o decisión a tomar, es binaria en este caso. | |
Lo primero que haremos será entrenar el modelo con un conjunto de vectores de entrada de dimensión 4, como podemos ver los vectores están etiquetados, el quinto campo de cada entrada contiene una clase binaria 1/0 indicando que hay compromiso o no de la cuenta bancaria, o en consecuencia si se procede con anular o no la transacción. La decisión sobre qué información utilizar para el entrenamiento debe ser tomada por un analista con conocimiento en dicho campo y fundamentado en experiencias (incidentes) reales a ser posible.
Alta,1300,Barcelona,1,0
Media,400.000,Panamá,1,1
….
Baja,5,Fiyi,1,1
Tras el entrenamiento se generará un árbol de decisión. Dependiendo del algoritmo en cuestión dependerá como queden dispuestos los nodos, las hojas, la anchura y profundidad del árbol, etc. Pero el fundamento es el mismo, tener un mapa de características que nos guiará hasta una decisión recorriéndolo desde la raíz hasta una hoja.
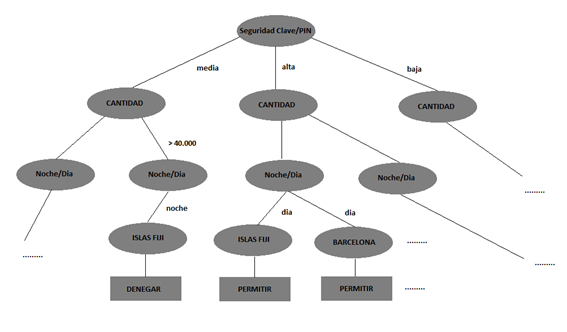 |
| Fig1: Modelo lógico de nuestro agente. |
Una vez definido el modelo, en este caso es un árbol de decisión, el autómata solo tendrá que seguir el árbol a través de los valores de los atributos hasta llegar a las hojas (decisiones). Por ejemplo para un cliente con una clave o PIN de fortaleza media, para una transferencia de más de 40.000$ en horario de noche (supongamos que de 8 PM a 8 AM) a una cuenta destino geolocalizada en Islas Fiji se lanzaría una acción de denegar la transferencia, exigir un segundo factor de autenticación o alertar de manera silenciosa a un equipo CERT de la entidad bancaria. Una de las características que nos gustaría destacar de este modelo ya que tenemos la oportunidad es la velocidad de respuesta (“ toma de decisión”), se puede observar que es un problema es de complejidad O{n} (orden n, recorrer en profundidad un árbol), lo cual lo hace muy indicado en entornos que requieran de respuesta ágil y sometidos a una tasa de consulta muy elevada.
Aprendizaje no supervisado + Mapa auto-organizado (redes de Kohonen)
El aprendizaje no supervisado puede parecer al principio más complicado de imaginar en funcionamiento. Pero con el siguiente ejemplo quedará claro cómo funciona y de paso mostramos uno de los modelos más interesantes como son los mapas auto-organizados ( Self-organizing Maps, SOM), ya que están inspirados en la biología, concretamente en la disposición de las neuronas relacionadas con el sentido del tacto.
Vamos ahora a suponer que nuestro sniffer de red registra tráfico y en lugar de comunicarlo a un IPS tradicional, que analizaría mediante una expresión regular (como hace Snort[1]) cada trama, crea con las características (campos de la trama, las flags TCP, IP origen, etc.) un vector de entrada y se lo pasa al modelo. Nuevamente el modelo responderá, veremos que de manera sutilmente distinta al ejemplo anterior, y al tratarse de un IPS de manera activa se tomará una decisión sobre dicho tráfico.
El modelo se crea mediante entrenamiento nuevamente, pero en este caso el conjunto está sin etiquetar, no hay información de si algo es “bueno o malo” o clase de pertenencia.
| IP-origen [192.168.1.2, 10.10.10.10, 8.8.8.8,…] | | Variable nominal |
| TCP-flags [0.0.0.1.1.0.0.0.0, 0.0.0.0.0.0.0.0.1,…] NS,CWR,ECE,URG.ACK.PSH.RST.SYN.FIN |
|Variable nominal |
| Diff de tiempo – respecto trama anterior (ms) y | | Variable numérica |
| 10.10.1.4 | 0.0.0.0.0.0.0.1.0 | 0 | |||
| 10.10.1.4 | 0.0.0.0.0.0.0.1.0 | 1 | |||
| … | |||||
| 10.10.1.4 | 0.0.0.0.0.0.0.0.0 | 5 | |||
Sin entrar mucho en detalles diremos que inicialmente el modelo es una retícula, que conforme transcurre el entrenamiento los nodos irán ajustándose sobre los datos de entrenamiento, creando áreas de mayor densidad de nodos (grupos o clústeres).
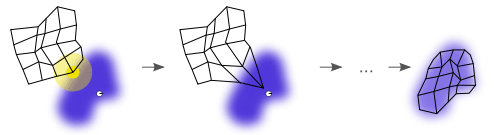 |
||
| Fig2: La retícula se ajusta sobre el espacio de soluciones. |
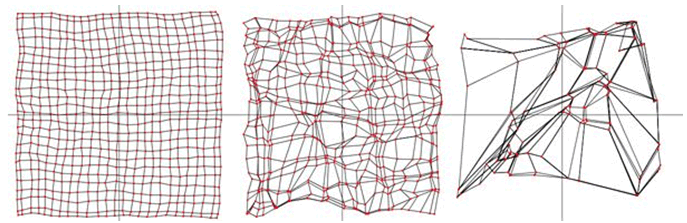 |
|
| Fig3: Además de ajustarse los nodos de la retícula se concentran, aumentan la densidad de estos en las zonas más representativas del espacio de soluciones. |
Terminado el entrenamiento la maya queda “fijada”, ahora nuevamente se aplicará al modelo cada entrada correspondiente a los segmentos TCP capturados. El vector incidirá sobre la malla quedando asociado a una concentración de nodos (clúster) en función de la distancia y la densidad de nodos respecto del punto donde incidió.
A continuación se pueden dar dos situaciones:
- La primera es que tras el entrenamiento se etiqueten los grupos formados de nodos por un analista que confirme que hay relación entre ellos. Al vector así clasificado se le aplicará la decisión que proceda con dicho grupo. Un caso de éxito de su aplicación es el expuesto en el artículo de 2009, “Building an efficient network intrusion detection model using self organising maps.” escrito por Mrutyunjaya Panda y Manas Ranjan Patra, donde tomando como conjunto de entrenamiento el kdcup99[2] se obtuvo un modelo capaz de detectar y clasificar distintos tipos de ataques de red.
- La otra situación es prescindir de etiquetado alguno, con lo que tendremos un detector de anomalías para los casos en que el vector de entrada incida muy retirado de cualquier concentración de nodos. Si el modelo fue entrenado con tráfico habitual de la red, las anomalías pueden ser clasificadas como ataques o incidentes por confirmar.
Aplicaciones
A día de hoy el uso de técnicas de “ machine learning” está más extendido de lo que en principio podríamos pensar en productos relacionados con la seguridad como SIEM é IPS. Aunque su aplicación no es novedosa en el campo de la investigación no es así en el mercado tecnológico. Este último está muy condicionado por modas o revoluciones de lo nuevo y podemos ver la incorporación de estas técnicas a productos de gama alta o en servicios de monitorización, a veces envueltas en cierta aura de misterio y a precios desorbitados. Más ofuscado aún es su uso en aplicaciones propias y no comerciales para la detección de fraude o robo de cuentas por parte de bancos o aseguradoras. Por esto, uno de los casos de éxito al que nos gusta hacer referencia es el del proyecto M.U.S.E.S[3], el cual está financiado por fondos europeos y cuenta con forja de software[4] bajo licencia GPL. En su caso, aplicado a la implantación segura de la política empresarial “ Bring your own devices” (BYOD). Y que es un ejemplo válido de como más adelante se puede derivar a un producto comercial.
Conclusión
Las técnicas de “ machine learning” pueden ser una poderosa herramienta en manos de investigadores y proveedores de productos tecnológicos centrados en la seguridad informática. Fuera de modas y revoluciones de lo nuevo, su divulgación debe ser responsable y ética con las expectativas ofrecidas por el estado del arte actual. Ha sido nuestra intención durante el artículo el transmitir de manera lo más simple posible y sin entrar en conocimientos demasiado profundos, los conceptos básicos que son necesarios para comprender las técnicas que aplica. No nos hemos detenido demasiado en temas como la base matemática requerida para la construcción de sus modelos (base teórica), o librerías de desarrollo (base práctica), para dar más relevancia al conocimiento de los conceptos fundamentales y ejemplos de demostración. Por lo que queda como tema pendiente para futuros artículos.
Referencias
[1] https://www.snort.org/
[2] http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html
[3] https://www.musesproject.eu/
[4] https://github.com/MusesProject
Autor: Juan Luis Martín
Departamento Auditoría